



最近AIの学習データ周りはいろんな意見が出ていますよね。ChatGPTなどの生成AIが一気に普及しましたから議論が加速しています。
著作権保護の観点からさまざまな団体も無断学習に対する反対声明を出しています。先日は「才能の民主化」なんて言葉も出てきました。
しかし、人間は便利なものは多少のリスクがあっても利用する方向に流れてしまうのが常。声を上げるのも必要ですが、しっかり自衛もしましょう。ちょっとしたことであなたのサイトをAIの学習から守ることができます。
ただし注意点(後述)もあるのでいろんな角度からの対策を考えておきましょう。
そもそもAIはどうやって学習している?
AIは大量のデータを読み込み、それらを使って学習します。この「大量のデータ」を得るのにインターネット上からテキストデータなどを集めているわけです。これをクローリングやスクレイピングと言います。それらで学習したものを使って回答を生成しています。
当然全てのサイトに許可をとっているわけはありませんから勝手に収集しています。そして、通知もなく勝手に使われているので気づかないと思いますがその対象にはあなたのサイトやブログも含まれています。無断で勝手に学習されるのは嫌ですよね。できれば学習させたくない方も多いでしょう。
現状はテキストデータが中心と思われますが、画像生成AIや歌、音声の生成AIが存在することを考えると自分の作品を公開している方は特に注意が必要です。
でも大丈夫、AIのクローリングを拒否することが可能です。ちょっとした設定を行なって自分のサイトをAIから守りましょう。
AIのクローラーをブロックする方法
概要
必要なことを言うと、「設定を書き込んだrobots.txtをサーバーのルートディレクトリに配置する」です。
Webに明るくない人からすると何を言っているかわからないかもしれませんが、詳しく解説していきますのでご安心を。
robots.txtに書き込む設定
robots.txtとは、検索エンジンなどのクローラーに対して自分のサイトをアクセスしていいかどうかを指示するファイルです。このrobots.txtに「AIのクローラーはこのサイトにアクセスしないでください」という設定が書けるわけですね。
主要な生成AIであるOpenAIのChatGPT、GoogleのGemini(旧Bard)、AnthropicのClaudeを全てブロックするには以下の設定を書きます。メモ帳など、なんでも構わないのでテキストエディタを開き「robots.txt」というファイルを作り、以下のコードをコピペしましょう。よく分からない!という方はこちらのリンクからダウンロードできます。
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: CCBot
Disallow: /内訳は次のとおりです。
- ChatGPT: GPTBot, ChatGPT-User
- Gemini: Google-Extended
- Claude: anthropic-ai, Claude-Web
CCBotはCommon Crawlという非営利団体が提供しているクローラーで、各種AIの学習データに利用されているようです。合わせてブロックしておきましょう。
形式は次のとおりです。
User-agent: クローラーの名前
Disallow: /こうすることで指定した名前のクローラーからのアクセスをブロックできます。もし新しくブロックしたいクローラーが出てきたらこの2行をrobots.txtに追記すればOKです。
サーバーに設置する
robots.txtができたら、サーバーに設置しましょう。今回はXserverを例に解説していきますが、どのレンタルサーバーでも作業は似ています。
ちなみに、もしある程度知見がある方はFTPツールを使ってそちらから操作を行なっても問題ありません。
サーバーにログインして、ファイルマネージャーを開く
各レンタルサーバーには通常、ファイルを操作する機能があります。ファイルマネージャーという名前のことが多いので探してみてください。Xserverの場合はログインして対象のサーバーの「ファイル管理」をクリックします。
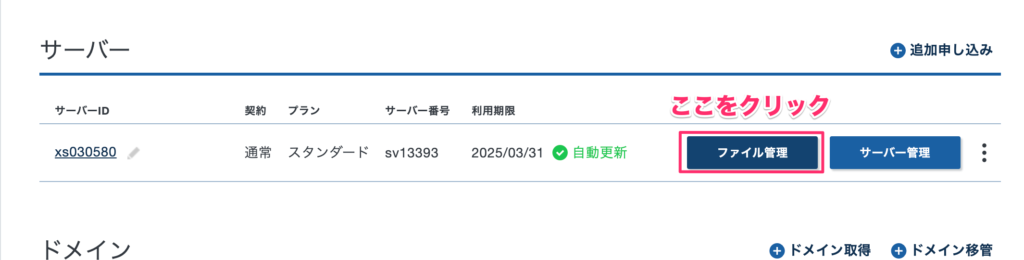
するとファイル操作画面に移ります。次のような表示になればOKです。
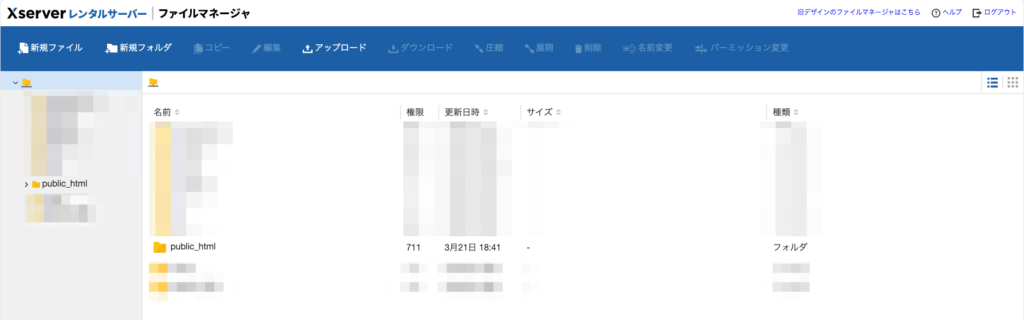
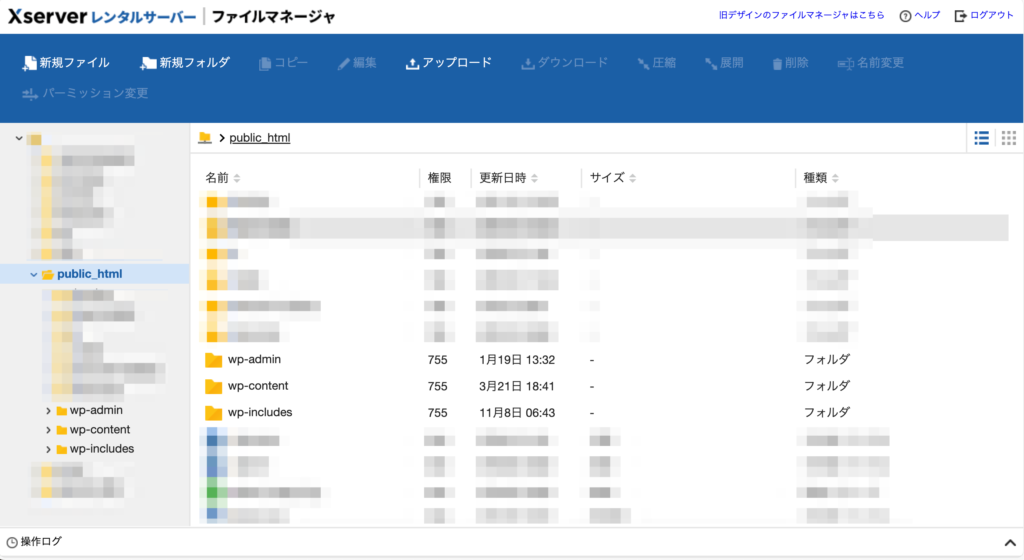
ルートディレクトリを探し、robots.txtを設置する
ではルートディレクトリはどこかという話ですが、Xserverの場合は「public_html」というフォルダです。WordPressを利用している場合は「wp-admin」「wp-content」のようにwp-で始まるファイル、フォルダが入っていれば正解です(下画像)。
さて、ルートディレクトリが見つかったらrobots.txtを探します。なければ設定を書いたrobots.txtを画面上部の「アップロード」ボタンからアップします。見つかったらそのrobots.txtを選択、画面上部の「編集」ボタンを押して設定を追記する形になります。robots.txtダウンロードリンク再掲
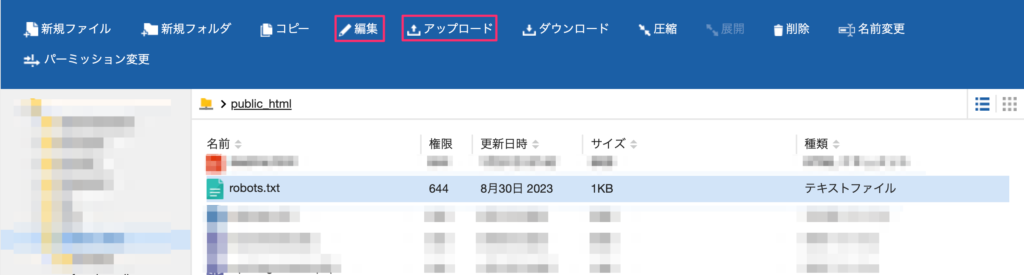
編集の場合、設定を書き込む画面になります。すでに書かれている設定は変更せず、その下に設定を貼り付けてください。コードを再掲します。
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: CCBot
Disallow: /実際の設定イメージはこちら。
設定を書き込んだら右下の「更新」ボタンを押して完了です。
設定がうまくいっているか確認する
設定作業が完了したら、正しく設定ができているか確認しましょう。手順は簡単で、自分のサイトのドメイン名の後ろに/robots.txtをつけてアクセスするだけです。
例えばこのサイトだったらhttps://itokoba.com/robots.txtとしてアクセスします。設定がうまくいっていれば先ほど書き込んだ設定内容がそのまま表示されます。これでAIに学習させないようにできているということです。

表示されない場合
うまく表示されない場合、画面にエラーが表示されていると思います。エラーの数字によって原因を推測できますので、もし失敗した方は画面の数字に合わせてこれから説明する対処法を試してみてください。
404エラー
数字が404の場合、Not Foundという「ファイルが見つからなかった」という意味のエラーです。その場合、
- robots.txtを配置した場所が間違っていないか、改めてルートディレクトリがどこかを確認する
- ファイル名が間違っていないか確認する
を行なってください。
403エラー
数字が403の場合、forbiddenという「閲覧が禁止されている」というエラーです。この場合はファイルの権限(パーミッション)が間違っている可能性が高いです。ファイルマネージャーに戻って設定を確認しましょう。
改めてファイルマネージャーからrobots.txtを見て、権限の欄を確認してください。
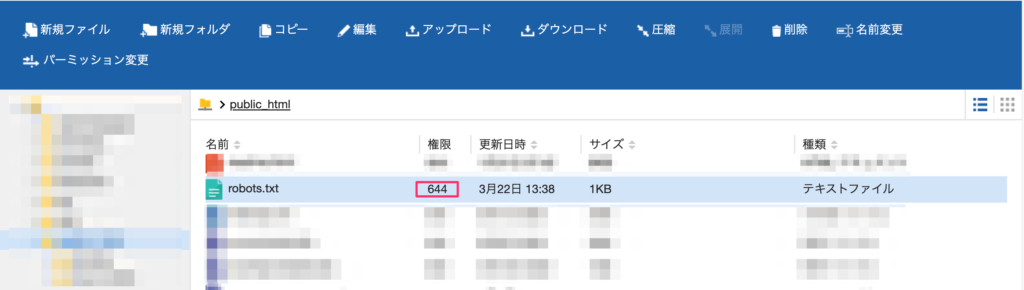
もし数字が644ではなく600などの場合、間違っているのでここを修正しましょう。画面上部の「パーミッション変更」を押します。
変更画面になったら、それぞれの「読み取り」をチェックしましょう。もしくは数字で644としても良いです(下画像)
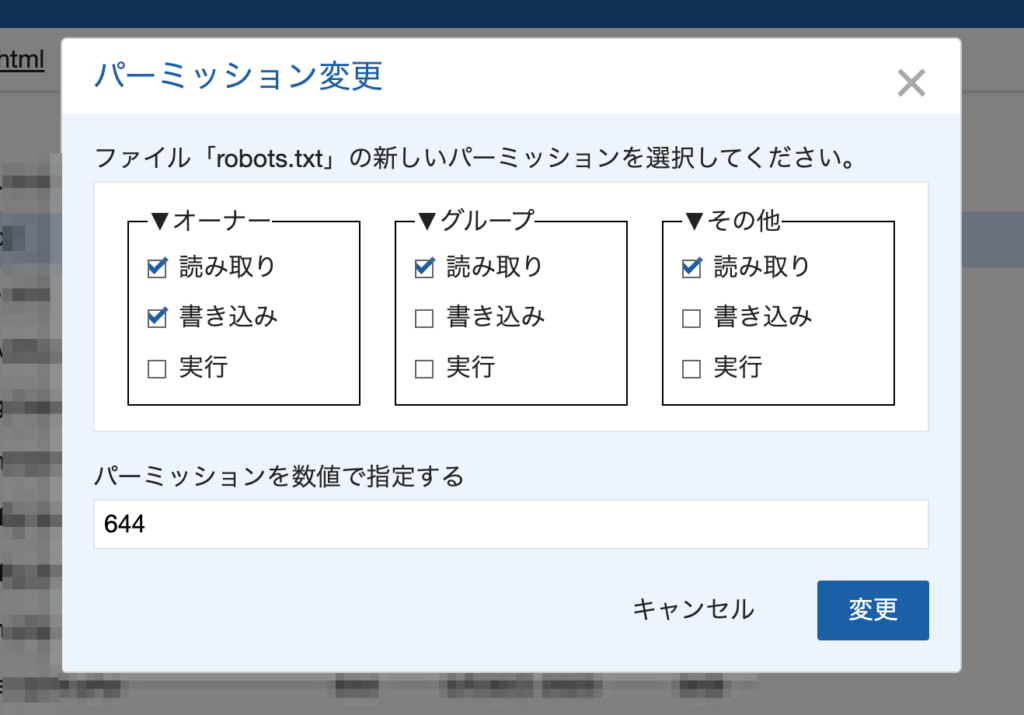
これでOKです。
注意点 |
一応今回の方法で効果があるとされているのですが、残念ながらクローラー名を隠されたりユーザーエージェントを偽装されたりすると効果がありません。
クローリングする側がちゃんと「私はChatGPTのクローラーです」と名乗ってくれなければブロックできないわけですね。クローリングして情報を取りたい側の発想からすればブロックされたくないので、掻い潜ろうとしてくる可能性が高いです。
なので他の対策も合わせて考える方が良いでしょう。


コメント